
5. 『パソコン国語国文学 第3章』DB-West編(1995年1月)啓文社
第3章 音声情報データベース
田原広史(大阪樟蔭女子大学 日本語研究センター)
1.はじめに
この章では「音声」に関するデータベースの概要と現状、さらに将来に向けての期待について扱う。おそらく読者の方々にとって、他の分野のデータベース以上にピンと来ないことと想像する。現実に、われわれの研究分野(国語国文学)における「音声」に関するデータベースはまだ発展途上にあり、これからのものなのである。
「音声」に関するデータベースが「テキストデータベース」と大きく異なる特徴(欠点?)としては、現在の電話通信網では通信回線を利用した検索サービスが不可能だということである。理由は、後に詳しく述べるが、データ量が膨大で、具体的に言えば、1秒の音声を聞くために3~4分待たされることになってしまうからである。したがって、「音声」に関するデータベースに関しては、それぞれの利用者がパーソナルデータとして手元に置いておく必要があるということになる。このことは、データをパーソナルなものとして扱うという点でパソコン向きだとも言えるかもしれない。
ここでは、「音声」に関するデータベースのことを「音声情報データベース」と呼ぶことにする。この「情報」の意味は「音声とその音声に関わる情報」のデータベースという意味である。単に「音声データベース」という呼び方もあり、同じような意味で使われることも多いのだが、「情報」という部分の持つ意味はかなり大きいので、ここではこのように呼ぶことにした。
この「音声情報」には、さまざまなレベルのものがある。最も単純な例をあげるならば、CDでは収録された曲ごとにプログラム番号がついているが、曲の位置という一種の情報であるプログラム番号を指定することにより望む曲が聞けるのであるから、これも一種の「音声情報」と言えるだろう。もっとも複雑な例では、CD-ROMからなるデータベースで、話者の出身地や年齢、発話項目等で検索をおこなうもので、たとえば京都出身の70歳台の女性の「アメ」という単語を含む発話をまとめて再生する、というような高度な検索も可能である。ただし、ここまでのことをするにはCDプレーヤのような再生機だけではだめで、パソコンを介する必要がある。
もう少し「情報」に関わる部分をあげるならば、「音声」に関連する情報、例えば話し手の属性に関する情報(年齢、出身地、性別など)や、「音声」そのものに関わる情報(音声、音韻表記、アクセント型、場合によってはその音声を機械分析した結果得られた高低のカーブといった画像データなど)がそれにあたる。この「情報」にあたる部分は、通常「テキストデータ」であるので、「音声情報データベース」は「音声」と「テキスト」の両方を含むマルチメディア的なものになる。
「音声情報データベース」という術語自体は、必ずしも情報が電子化されているという定義を含んではいないが、一般的にはパソコンで扱える形であることが前提となっているので、ここでも電子化テキストからなるものを対象とする。したがって、たとえばNHKの『全国方言資料』という、方言の会話をカセットテープに収め、詳細な文字化テキスト資料を冊子として添付しているようなものは、このままの形では「音声情報データベース」と呼ぶことはできない。
この章では、「音声情報データベース」の概要、現段階での作成、利用状況、国語国文学分野(主に国語学分野になるだろう)における実例の紹介と今後の見通しといった流れで話を進めていく。
2.音声情報データベースとは
2-1 生データからデータベースへと向かう過程
収録した音声から「音声情報データベース」を作成するまでには、「生データ」、「データ」、「データベース」という術語で呼び分けられる過程がある。
ふつうわれわれは「生データ」と「データ」を区別せず両方とも「データ」と呼ぶことが多いが、データベースを語るときこの二つははっきり区別する必要がある。
音声資料における「生データ」とは収録した音声そのものである。方言音声の収録を例にとると、収録の際にはしばしば必要な音声以外に、説明などの余分な会話、雑音の混入、音声と音声の間隔の不揃い、録音失敗後の録り直しによる収録順序のくずれなどが起こる。収録者自身でさえこのままでは資料として使えず、そのままの状態で数年から十年も経つと、もはや何が収録されているかさえ分からなくなることもある。いわんや他人が利用することはまず不可能である。過去に、たいへんな手間と労力をかけて収録したにも関わらず、このようにして使えなくなってしまった「生データ」が山のようにあると想像する。これらの「生データ」は、万人が利用でき、保存に耐える「データ」とはなり得なかったということである。
この「生データ」から雑音を取り除き、順序を並べ直し、整理整頓したものが「データ」ということになる。「生データ」を「データ」の段階にまで仕上げておくことが、長期保存および公開、さらには「データベース」の作成、利用への必須条件と言える。録音テープ資料として市販されているもの、たとえば、前節であげた『全国方言資料1~11』(1981,日本放送協会編,日本放送出版協会)、『方言談話資料1~10』(1979~,国立国語研究所,秀英出版)、松田正義他『方言生活30年の変容』(1994,松田正義、糸井寛一、日高貢一郎,桜楓社)はこの「データ」である。これらは公開されている方言音声の「データ」の中でも非常に良質なものである。しかし、残念ながら現在われわれの分野には、この「データ」と呼ばれるものどまりで、次の段階である「データベース」は皆無に近い。「データ」でさえも、入手可能なものとしては上にあげた三つしかないのである。
そして最後に「データベース」である。「音声データベース」の定義は次の通りである。

もう少しかみくだいて説明しよう。まず「音声資料」は上記「データ」のことである。次に「大量」の部分。これは定義する上で必須の要素ではないし、何分以上だったら大量なのかといった点で漠然としているが、データベースがさまざまな目的で利用される運命にあることを考えれば、結果的に大量のデータになってくるだろう。
次に「蓄積し」の部分。「データ」として考えるならば、蓄積するメディア(記録媒体)に制限はない。すなわち、昔ながらのレコードでもオーディオ用のカセットテープ(以下「アナログテープ」)でもDAT(ディジタルオーディオテープ。ディーエーティーあるいはダットと読む。装置の仕組みはVTRと同じ構造だが、大きさはふつうのカセットテープの約半分。高品質録音ができる)でも、はたまたCD、パソコンやワープロで使うフロッピーディスク、CD-ROM(超大容量のフロッピーディスクと考えてよい。ふつうのフロッピーディスクの500枚以上の情報がはいる)でもよい。次の節でこれらメディアの比較をする。
ここまでは上記「データ」の定義部分だが、次の「必要に応じて必要な部分を比較的簡単に利用できる」というところがデータベースならではの定義部分である。ごく簡単に言えば「望む音声が即座に聞ける」ということに尽きる。言ってしまえば簡単だが、「データ」を「データベース」にするには、音声データ以外の情報を加える作業が必要になる。
基本的な考え方は、テキストデータベースとまったく同じである。テキストデータベースの場合は、最終的にたどりつくものが文字であらわされる単語、文、文章であるが、「音声情報データベース」では最終的な目標が「音声」となる。
具体的な作業については追って述べるが、実際にこの目的を満足いくように実現するには革命的な技術革新が必要であったし、まだ十分とは言えず、これからも必要である。
2-2 音声情報データベースにおけるメディアの比較
前項では、「データ」を蓄積するメディアに制限はないと言ったのだが、より適したものが「データベース」のメディアとして最終的に選択されることになる。多少横道にそれるかも知れないが、これらのメディアの概要を説明し、良い点、悪い点を比較検討してみる。
音声データを蓄積できるメディアの種類は多種多様だが、形状という観点と記録される信号形態(蓄積されているデータの形)の2点から分類が可能である。形状はテープ型のものと円盤型の2種類、信号形態はアナログとディジタルの2種類がある。現在、使用可能なメディアをあげ分類してみる。

2-2-1 テープ型
まず、テープ型のものから比較してみる。アナログテープ、DAT(ディジタルオーディオテープ,ディーエーティーあるいはダット)、およびDCC(ディジタルコンパクトカセット,ディーシーシー)である。DCCは、MD(ミニディスク)とならび最近登場した新しい技術によるものだが、簡単に言えばカセットテープと同じ規格の装置で、録音の方式はDATと同じ原理(ディジタル)によるものである。
テープ型のものは構造上の制約で、ある音声を聞きたい場合、頭から何分何秒というふうにしか示すことができない。カウンターを見ながら、そこまで早送りしたり巻き戻したりする手間は大変である。聞き比べたい音声がテープの始めと終わりに入っていたなら、自分でダビング編集をしない限り、交互に聞き比べることはできない。
DATは、アナログテープやDCCに比べるとかなりスピードは早いものの、早送り巻き戻しという原理は同じである。ただし、DATとDCCはCDと同じようにインデックスあるいはプログラム番号(1~99番まで)が付けられるので、たとえば5番と指定してスイッチをポンと押せば、あとは5番目の項目まで機械がテープを送ってくれるという利点はある。すなわち、操作性の点ではDAT、DCCはアナログテープとCDの中間に位置していると言える。
音質に関しては、アナログテープはアナログ、DAT、DCCはディジタルという違いがあり、音質、保存の点からはディジタルの方が勝る。こうしてみるとDAT、DCCはアナログテープの欠点を完全に克服するものであるということができる。極論すれば、DATあるいはDCCがあればアナログテープはまったく必要ないということになる。ちょうどCDとレコードのような関係である。
しかし、現実には今のところ、CDがレコードを駆逐したように、DATやDCCがテープを駆逐する様子はない。方向としては、先発のDATに加えて、アナログテープとDATの中間形態であるDCCが改めて登場したわけだから、多様化が進んでいると言える。このDCCは、よく言えば両方のよい面を組み合わせたと言えるし、悪く言えば中途半端な妥協の産物のようにも見える。妥協のよい点としては、DCCプレーヤではアナログテープも再生できるので、一般オーディオファンにとっては魅力的である。逆に悪い点としては、アナログテープが再生できるようにするために構造上無理が生じ、録音する信号を操作してかなり情報量を圧縮せざるをえなくなったことである。
「音声情報データベース」を作成する際の編集作業をパソコンでおこなうことを考えると、信号に操作が加えられていることは致命的である。パソコンで音声データを扱うにはデータ形式はできるだけ単純な方が望ましい。この圧縮に関しては円盤型のMDにも採用されているので、データベース用のメディアとしては同様のことが言える。
このように、テープ型のメディアは、今後一般市場において三者のバランスがどのようになるのか、もう少し先を見ないとわからない状況であるが、結論としては、データベース本体の形状としては目的の音声にアクセス(目的とする音声にたどりつくこと)する手間を考えると、テープ型は適していないと言える。
ただし、DATはデータベース作成の観点からは、マイクから直接音声を収集する段階では不可欠のものになりつつある。最初の収録段階で良質の録音をおこなっておかなければ、その後の編集、再生技術がすばらしくても収録時の音質を上回ることができないからである。また、保存に関してもDATはコンパクトで場所をとらず、アナログテープのように転写、伸び等の劣化も少なく、今後とも用いられていくだろう。
2-2-2 円盤型
次に円盤型のメディアを比較してみる。円盤型の中で唯一のアナログ信号であるレコードはすでにCDに凌駕されているのでここでは除く。したがって、円盤型はすべてディジタル信号で記録されているということになる。円盤ディジタル型メディアは、耐久性の面でもテープ型と違ってヘッドと媒体との間に物理的な接触がなく摩耗しないという特長がある。また、アクセスが瞬時にでき、前項の音声データベースの定義である「必要に応じて必要な部分を、比較的簡単に引き出して利用できる」を満たすためには円盤型のものである必要がある。元来、円盤型の欠点であった容量の少なさも記録密度の飛躍的な増大によって実用に十分耐えるものとなっている(CDで最大70分程度)。
円盤型のメディアには、再生のみのものと録音可能なものとがある。再生のみのものとしてはCD、CD-ROM(シーディーロム)があり、録音できるものとしてはMD(ミニディスク)、MO(光ディスク)、FD(フロッピーディスク)、HD(ハードディスク)がある。このうちCDはかなり普及しており、操作が簡単なことからもデータベースのメディアとしては魅力的である。近年登場したMD(ミニディスク)はCDの操作性に加えて、録音ができるという利点がある。MDはDATの機能を生かしつつ、それを円盤型に変えたという見方もできる。ただし、テープ型のところでふれたように、MDは記録方式が特殊であり、データベース用のメディアとしてはパソコンと相性がいま一つかもしれない。
次にCD-ROMとCDの違いを説明する。外見上はCD-ROMとCDは同じものである。CD-ROMとCDの違いを知らずに、「CDプレーヤに入れてみたが音がでない。不良品ではないか。」という苦情を受けることもけっこうある。それでは何が違うのかというと、記録の仕方が違うのである。CDはレコードのようなイメージで記録されており、一曲終われば次の曲に移っていく、音専用のメディアである。ちなみにCDはレコードとは逆に内側から外側に向かって針(ヘッド)が動いていく。再生機も専用のものを使い、それに入れれば誰でも即座に再生できる。
一方、CD-ROMは前項の説明でも触れたように、書き込みはできないが構造上のイメージはフロッピーディスクの仲間である。中に収める内容も音に限らずテキストデータも画像データも思いのままである。したがって「音声情報データベース」には最も適しているメディアということができる。ただし、必ずパソコンおよびCD-ROMを再生する装置が必要で、さらに加えて特殊な音声ボードやソフトウェアが必要となるので、われわれの分野の研究者レベルで普及するのはもう少し先の話かも知れない。
残りのMO(光磁気ディスク)、FD(フロッピーディスク)、HD(ハードディスク)のうちFDは音声データに関しては容量が小さすぎて問題にならない。1MB分の高品質の音声とは時間にして30秒にも満たないものだからである。MOは書き込みができてしかもFD120枚分の容量がある比較的新しいメディアであり、将来的に見てもっとも有望なメディアである。1994年夏に倍密度(230MB)のものが登場し、今後あっという間に普及するだろう。現在、音声編集をおこなう上で欠かせないものとなっている。HDについては、最近では500MBとか1GB(1024MB)のものが出回っており、十分活用の価値がある。HDは構造上持ち運びができないので、データの受け渡しの手段としては使えないが、編集作業をおこなったり、検索した音声を一時的に蓄えておくような使い方は今後ますます盛んになっていくだろう。
2-2-3 まとめ
以上、メディア別にそれぞれの特徴とデータベースとの相性について見てきたわけだが、最後に各メディアがデータベースのどの過程で使われるのに適しているかという観点から整理してみる。
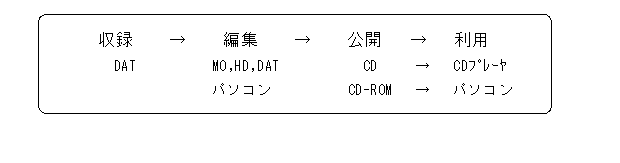
まず、「生データ」を収録する段階ではDATが適している。より良い音質で収録ができ、ディジタル信号のまま加工できるという点でパソコンとの相性もよいからである。次に編集の段階ではMOやHDにデータを一時的に蓄えつつ編集作業をおこなう。CD用の音声についてはDAT2台を組み合わせてダビングしながら編集する方法でもよい。データベースとしての公開はCDあるいはCD-ROMでおこなう。利用時にはCDの場合はCDプレーヤで、CD-ROMの場合はパソコンで利用する。パソコンで利用する場合は一時的に検索データをHDに蓄えながら利用することになるだろう。
公開はCDあるいはCD-ROMで、としたがMO自体で配布することももちろん可能である。コストとの関係になるのだが、CDあるいはCD-ROMをプレスするには400枚で(最低400枚単位でおこなわれている)最低4~50万円かかる。単語などの細かく分割した音声データだと業者側の編集作業の手間がかかるのでもっとかかる。実費で1枚1000円以上になるわけである。
MOだと自分でデータを詰め込んでコピーするだけだからメディア代だけで済むが、MOディスクは現在、120MBのもので一枚3000円程度するので、結局大量に作成する場合はCDあるいはCD-ROMの方が断然安上がりということになる。しかも最近CD、CD-ROMを自作できる機械が7~80万円程度で出回り始めているので、データベースの試作品も今後ますます作りやすくなるだろう。
このように、さまざまなメディアが「音声情報データベース」の作成、利用にはかかわってくることがお分かりいただけたと思う。
2-3 音声情報データベースにおける音声データの扱い
前項での結果、候補として残ったものの条件を考えてみると、信号形態がディジタルであること、そして容量がある程度(少なくとも100MB以上)あるものが利用できることになる。容量についてはデータがいくつにも分割されるのは検索などの面でも煩雑であるし当然であろう。ただ信号形態がなぜディジタルでなくてはならないのか。それはデータの蓄えやすさ、加工のしやすさに起因する。
われわれが耳で聞く音は連続的な空気の振動からなっている。前項であげたアナログテープやレコードはこの振動を連続的なままで記録したものである。音声は音色と高さと強さの3要素からなるのだが、これらの要素を分離しないで連続的な波形のイメージのまま保存したと考えてよい。
この連続的な信号をアナログ信号と呼んでいる。ラジカセのボリュームや音質のつまみをいじることによって、連続的に音の強さを変えたり、高い部分を強調したりすることができるのは、このアナログ信号の特徴である。欠点は電圧などが一定しないとそれがそのまま原音のゆがみに反映されてしまうことである。ダビングをすることに関しても、音声波形にトレーシングペーパーを当ててなぞるようなものであるから、完全に元の音声信号どおりにはならないし、なぞったものを元にして、また別のコピーを作るなら、ますます元の音声波形から離れていく。すなわち、アナログ信号のダビングでは音質低下が宿命的なものであるということである。
一方ディジタル信号は、この連続した波形の上に方眼用紙を当ててマス目ごとに縦横の座標を抜き出したようなものである。この際、音の3要素は、縦軸に強さ、横軸に高さ、グラフのパターンが音色というように要素に分解されて記録される。座標をすべて記録しておけば、別の紙にその座標データに基づいて、まったく同じ波形が再現できるわけである。いったんディジタル化(座標に分解)してしまえば原理的には2度とデータは変わらない。これは、フロッピーディスクを次から次へとコピーしても、新しくコピーしたフロッピーの文書内容が変わらないのと同じ理屈である。
したがって、音質の劣化は最初に原音をディジタル化する際にしか起こらない。元の音声がどれだけ忠実にディジタル化されているかは方眼の目の粗さによる。目が粗ければ近似値になるし、目が細かければ元の音に限りなく近づいていく。ただし、データの量はマス目の数に比例するわけだから、10×10だったら100マスで済むが、縦横倍のマス目にするなら20×20=400マスというように4倍必要になる。
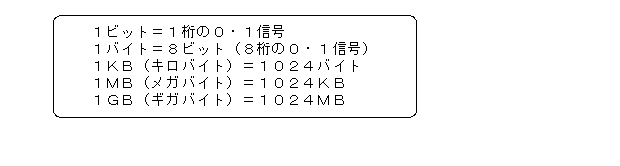
現実には横軸(時間軸)に沿ったほうのマス目が1秒間に48000マス(DAT)とか44100マス(CD)であり(それぞれサンプリング周波数が48kHz、44.1kHzという)、縦軸(強さ軸)に沿ったほうのマス目が65536マス(16ビットの量子化と呼ぶ。DAT、CDとも)といった信じられないくらい細かいものである。この結果、CDでは1秒間に44100×65536=2,890,137,600(約2億8900万)マスもの方眼用紙を使うことになってしまうのである。
これだけのマス目を使えばデータ量もものすごいものになる。たとえばCDでは、1秒間に44,100×16ビット=705,600ビット=88,200バイト=約86KBになる。ステレオだと左右2チャンネルあるからこの倍である。1時間(3600秒)では、88,200バイト×3,600秒×2=約600MBにものぼる。
音声データをデータベースとして使用する場合、使用目的とも関連するのだが、検索、編集、機械分析あるいは音声合成というような処理をおこなう際には、このディジタル化は避けて通ることのできない道である。ディジタル化を実現するにはこれだけの量の信号処理を可能にする演算速度と、処理した膨大な信号を蓄えるための入れ物が必要となるが、われわれの身近にあるCDプレーヤを見れば分かるように、この程度の技術はすでにわれわれの手の届くところまで来ているのである。
2-4 音声情報データベースの種類
ここでは音声情報データベースの種類を確認しておきたいと思う。「音声情報データベース」は大きく2種類に分けることができる。一つはCD(あるいはDAT)によるもの、もう一つはCD-ROM(あるいはMO)によるものである。
CDによるものは、前項でもふれたように音声とプログラム番号のみからなっている。CD本体には音声しか入れられないから、これ以上の情報は付加することができない。別途フロッピーディスクで補助的に情報を添付することはできるが、CDの場合は、音声部分と情報部分を機械的に連動させることはできない。すなわち、フロッピーで提供された情報を検索した結果から直接音声を引き出すことができず、手動でCDプレーヤを操作する必要があるということである。これに加えて、CDのプログラム番号は1番から99番までしか付けられないという制限がある。一項目が30秒以上もある文章のような単位を扱う場合には、これで十分なのだが、一項目が1秒程度の単語単位の細かいデータベースを作成するのには向いていない。
CD-ROMによるものは、CD-ROM内部に情報部分を混在させることができる。場合によっては検索プログラム自体を内部に含めることもできる。CD-ROMによる「音声情報データベース」はパソコンと非常に相性がよく、いかに小さな単位であろうと、音声データが1000個でも2000個でも縦横無尽に検索し、検索された音声データを別のメディア(HDやMO)に保管したり、DATやアナログテープに編集しなおしたりして、別の観点のデータベースとして再編成することもできる。逆に言えば、ここまでできないと本来の意味でのデータベースと呼ぶことはできないのである。
CDでは音声信号をディジタル化する際のデータ形式が一種類しかない。前項でふれたマス目の横軸(時間軸)に当たる部分であるが、サンプリング周波数44.1kHz(1秒間に44100回のサンプリング)に統一されている。DATでは48kHzとCDより高い。この数が大きければ大きいほど源音に忠実になっていくが、逆に音質が良くなればなるほどデータ量は増える(収録時間は減る)ことになる。
人間の声をデータベースにする場合は、実際はCDほどサンプリング周波数を上げる必要はなく、16kHz程度で十分である。44.1kHzを16kHzにした場合、データ量は3分の1近くになる。また、音声データベースの場合、必ずしも左右2チャンネル(ステレオ)である必要もないから、片チャンネルのみでデータベース化するならば、CDの5~6倍の時間音声を入れることができる。ざっと5~6時間分の単語情報であればかなりのものである。一単語約2秒として、10000単語収録できることになる。これが規格化されたCDならば、音は不必要なほど高品質でステレオだが、1800単語しか収録できず、しかも18単語につき一つしかインデックスが入れられないのである。
この点、CD-ROMであれば、何種類かのサンプリング周波数の選択が可能であるから、このような離れ技が可能になる。この点でもCD-ROMが「音声情報データベース」向きのメディアだということがわかるだろう。
3.音声情報データベースの現状
2節では主にハード的なことを中心にして「音声情報データベース」というものをとらえたが、3節ではソフト的すなわち、現在どのような「音声情報データベース」が存在するのか、どのような使われ方をしているのか、そして将来の可能性はどうなのか、といったことについて、具体例を紹介しつつ述べる。
3-1 日本にはどのような音声情報データベースがあるのか
日本国内で作成されている音声に関するデータベースは、工学分野の音声技術開発を目的としたものがほとんどである。音声技術開発とは主として音声自動認識装置がどのくらいうまく認識できるかのテストに使うとか、合成音声をつくる場合のデータとするものであり、ほとんどが共通語音声を意識したものである。これらの「音声情報データベース」には「○○音声データベース」といった名前が付けられていないものも多いし、市販されているわけでもない。そこで、以下には音声データベース作成に関わっている研究機関をあげるにとどめる。
通産省電子技術総合研究所(電総研)、社団法人日本電子工業振興協会(電子協)、国際電気通信基礎技術研究所(ATR)、松下中央研究所などの研究機関や、東北大学、筑波大学、音響学会などが積極的に関わっているが、単語(および少数の文)が中心で、音韻論的観点(特に音色)からのバランスが重視してある。共通語、単語中心、音韻バランスの重視が三つの特徴であるが、目的からいって当然と言える。
一つだけ紹介すると、上記「電子協」の作成した「日本語共通音声データ 地名:男性」(CD版)は、99の地名(はちのへ、さっぽろ、よこて、あさひ、へきなん、るもい、てんどう、かぞ、うおづ、こうべ、くれ、べっぷ、・・・)を4名の男性が計4回ずつ延々と読み上げているものである。
このような音声技術開発目的のデータベースは、これまでに述べた「音声情報データベース」の定義にあてはまるものであるが、「情報」の部分に関しては、その音に含まれる詳細な音素、音声情報(音色に関する情報)が中心となる。場合によっては、さらに細かいスペクトル情報も記録されているものもある。「音声」の部分は基本的にはそう違いはないのだが、「情報」の部分は目的によってかなり違ってくるはずである。たとえば、国語学、方言学の分野においては、話者の詳細な情報が加えられるだろうし、アクセント、イントネーションなどの韻律情報(高さ、強さに関する情報)も当然加わえられるだろう。
国語国文学分野におけるデータベースとしては、平成元(1989)年度~4(1992)年度にかけておこなわれた文部省重点領域研究「日本語音声の韻律的特徴の実態とその教育に関する総合的研究」(略称「日本語音声」、研究代表者
杉藤美代子)において、全国各地の方言話者に対する同一の単語、文、テキストによる音声の調査、収集の試みがなされ、そのうちの一部についてデータベース化をおこなったものがある。国語国文学分野において、正確な意味での「音声情報データベース」と呼べるものはこの研究中に作成されたもの以外には存在しないといってもよいだろう。次の項では、この「日本語音声」における「音声情報データベース」について紹介する。
3-2 「日本語音声」における「音声情報データベース」
「日本語音声」は大きくA~Dの四つの班に編成されていた。それぞれ、A班は「音声の収集と研究」、B班は「音声データベースの作成と利用」、C班は「音響的、生理的研究と言語理論」、D班は「日本語教育及び国語教育への応用」と題し研究を進めた。
この研究の大きなセールスポイントの一つは、データベースを作るということであり、そのために当時できうる限りの良質な録音資料を収集しようという意志統一があったということである。そのために録音にはDATを用い、録音環境にもできるだけ注意を払った。DAT録音と録音環境の向上、たったこの二つのことを徹底するだけでもかなりの労力が費やされた。たとえば、収集にとりかかる前にDATの使い方およびよりよい録音の方法などについての研究会、講習会を泊まりがけでおこなったりもした。100名を越す共同研究であるから仕方がなかったとは言えるが、そのかいあって、収集された音声資料は今までおこなわれてきた方言調査の録音資料と比べて格段に高品質かつ等質なものである。
「日本語音声」の収集に関する調査は大きく3つに分けられる。「100地点調査」「主要都市調査」「その他の調査」の三つである。以下、それぞれについて具体的にどのようなデータベース化がなされたのか、あるいは今後なされる可能性があるのかについて簡単に紹介する。
3-2-1 100地点調査
「100地点調査」は全国から100地点を選んで高年層、中年層各一名に関して、全国同一の調査票で調査をおこなったものである。単語中心であることは、前述の工学系データベースとよく似ているが、収録する単語を選ぶ観点がまったく異なっている。「日本語音声」の方は、類別語彙を含む、アクセント体系を中心としたものとなっている。これにいくつかの短文、日本語教育で使用する簡単な日常会話文、二つないし三つの文章、数字、五十音図、母音などを含めた、1400項目にものぼるものである。
「100地点調査」の音声資料はかなりの部分がデータベース化された。この分野における「音声情報データベース」の皮切りとなるものだけあって、試作品的にさまざまな形のデータベースが作成されている。
まず、「桃太郎・天気予報」(文章項目)をCD化したものが作成された。これは、昔話の桃太郎の出だしの部分を方言に訳して発話したもの、教科書通りに読んだもの、一分程度の天気予報の原稿をそのまま読み上げたものの3種類の発声が、21地点の話者について収録されている。
次に、4人(アナウンサーおよび盛岡市、京都市、鹿児島市の高年層話者)について、ほとんどすべての調査項目を収録したCD(2枚)がある。さらに同じ方法で、日本を東日本と西日本に大きく分け、地点についてはほぼすべてをカバーし、調査項目については半分程度をCD化した(東日本5枚、西日本6枚)。
以上がCDによるデータベースである。「100地点調査」に関しては、CDだけでなく、CD-ROMによるデータベースも「桃太郎・天気予報」「疑問文イントネーション項目」「音声・アクセント項目」の三種類の項目について作成された。「桃太郎・天気予報」に関しては、CDのものと内容は同じであるが、地点がさらに追加され、計44地点収録されている。「疑問文イントネーション項目」も44地点について、「これ、エビ?--うん、エビ。」というような簡単な「疑問-返答」の組み合わせが26セット収録されている。「音声・アクセント項目」は、方言の母音、連母音の訛音(なまり)を含む18単語、類別語彙が18語収録されており、地点は80地点にもおよぶ。
以上が100地点調査の概要とデータベース化の状況である。CDによるデータベースに関してはプレーヤで簡単に聞けるのでよいのだが、CD-ROMのものに関してはかなり問題がある。このデータベースの場合、検索用のプログラムも同時に開発し、CD-ROM内部に納められている。パソコンで利用する場合、いったんパソコンのハードディスクに検索プログラムと話者の出身地等の情報、単語の拍数等の情報をインストールして(移し換えて)からでないと使えない。しかも、使用機器構成が複雑でかなりの出費を余儀なくされる。おそらく、このCD-ROMを持っている人のほとんどが、検索うんぬん以前に、まず中味を聞きたくてたまらないのだが聞くことさえできず、「宝の持ち腐れ」になっているに違いない。幸い腐りはしないが、できるだけ早いうちに機器等の使用環境が整って欲しいものである。
3-2-2 主要都市調査
「主要都市調査」は全国各地から主要13都市(札幌市、弘前市、仙台市、新潟市、東京都、名古屋市、富山市、大阪市、高知市、広島市、福岡市、鹿児島市、那覇市)を選び、各都市原則として70名の録音資料を収集した。発声者の年齢構成等は、高年層、中年層、若年層の3世代は男女各5名、中学生、小学生の2世代は男女各10名である。各世代まんべんなくカバーするように配慮したのは、後日のデータベース化をふまえてのことである。特に中学生、小学生が他の世代の倍の人数みてあるのは、昨今の日本語の変化の速度を考慮して決定された。
この録音資料は「日本語音声」期間中はデータベース化されなかった。データの量が膨大(DAT1000本以上ある)なので、とりあえず、ダビングするので精いっぱいだったのである。平成5年より5年計画で、新たな文部省科学研究費成果刊行の助成を受け、「日本主要都市方言音声データベース(JCMD)」(同作成委員会委員長
田原広史)として現在データベース化を進めている。平成5年度は、4都市分について朗読項目「天気予報」の一都市につき各世代20名分のCD化をおこなった。今後、残りの都市に関しても同様のものを出していく予定である。
同時進行で、一つは他の単語、文項目に関しても、最初に述べた方法にしたがってコンピュータによる編集、もう一つは話者のフェイスシート(名前、住所、言語歴などが含まれている)のデータベース化、調査項目(13地点それぞれに異なる)のデータベース化および索引づくりを続行中である。これらのデータは最終的にはCD-ROM化をめざすが、これからの数年のパソコンおよび音声関連の周辺装置の進歩と普及をにらみながら、CD-ROM化のタイミングを測っていく予定である。
このように、研究者が簡単に利用できるのはまだ先のことになるが、テープの整理、編集作業はできるかぎり早くやっておかないと、収録内容が分からなくなってしまう可能性が高い。2-1で述べたように、「生データ」を「データ」に仕上げておく必要があるわけである。今きちんと整理しておけば、10年後、100年後に向けて大きな遺産となるが、今ほっておくとすべてが無駄になる。データとはそういう宿命を持っているものだが、音声データは特にその傾向が強いのである。
3-2-3 その他の調査
「その他の調査」はA班以外の班が独自に収集したものが含まれるが、データベース化されたものとしては、「琉球方言」「アイヌ人の話す日本語」「日本語を学ぶ外国人の話す日本語」「各地の小学生の朗読」「邦楽と洋楽の歌唱」(以上CD)、「無型アクセント方言地域の音声」(カセットテープ)、「四つ仮名、二つ仮名、一つ仮名方言地域の音声」(カセットテープ及びビデオテープ)、「アナウンサーの音声」(ビデオテープ)がある。今後も各研究グループから整備された音声資料が刊行されていくだろう。
4.おわりに
以上、この章(第3章)では「音声情報データベース」に関する紹介をおこなった。将来の見通しとしては、今後ますます音声関連のパソコン環境が整っていくことと思われ、そう遠くないうちにCD-ROMをメディアとしたデータベースが一般に普及していくことと思われる。
現段階でもっとも難しいのは、テキスト情報を検索した結果から、音声データを引き出して来て、再生したり、再編集したりする市販のデータベースソフトがないことである。「テキストデータベース」、「音声編集」を作成、管理するよいソフトはそれぞれにあるのだが、この二つを同時にこなす「統合化ソフト」となるとなかなか難しい。
音声に関しては信号形式の規格がまちまちで、統一がなかなかなされないことが普及しない最も大きな原因であるように思われる。将来的には規格の統一がなされ、環境も整ってくるだろう。われわれDB-Westのような研究者団体が中心となって、積極的にガイドラインを設けていくことが必要であろう。
音声に限らないのだが、データベース作成にあたっては、関連データの集中管理がおこなわれる必要がある。情報サービスの拠点となるべく活動をおこなっているDB-Westのような会では、実際にデータベースを作成し、規格化をはかっていくと同時に、今までに収録されたまま各地に埋もれている音声および生資料を発掘し、リストアップしていくことも、直接データベースとは関係ないが、今後必要な作業だと考えている。
参考文献および解説
【オーディオ関係】
「音声情報データベース」をパソコンで利用する場合、音声信号のディジタル化の仕組みをある程度知っておく必要がある。しかし、残念ながら国語国文学分野の立場から音声処理を簡単に説明してある本はない。よって、文献としては、工学関係の立場から解説してあるもの、あるいはオーディオマニア用に解説してあるものを参考にすることになる。工学系の立場から書かれたものは、ディジタル化の理論を公式やプログラムを使って説明したものが多く、われわれの分野の者には読みにくい。一方、オーディオマニア用に書かれているものは、機械の仕組み、配線図などが中心のものもあるが、できるだけ数式なしで原理をうまく説明してあるものもある。後者の方がお勧めである。以下に3冊あげておく。
『デジタルオーディオのすべて DA変換技術をわかりやすく解説』(1994.8
井上千岳 電波新聞社 1900円)は、まえがきで「回路図や数式は原則として使わず理屈だけで納得してもらう」と書いてあるとおり、原理をとても分かりやすく説明してある。ディジタル化(サンプリング周波数、量子化)の原理、DA(アナログからディジタルへの変換)、AD(ディジタルからアナログへの再変換)、最近、DCC、MDに採用されたデータ圧縮技術の仕組み、などについて知る場合にはこの一冊で十分満足できる。
『おもしろオーディオQ&Aブック 差がつく現代サウンド常識』
(1992.11,入江順一郎,音楽之友社,850円)は、オーディオに興味のある人にとっては楽しく読める本である。CD、カセットデッキ、DCC、MD、DATについてふれてある。内容はごく入門的であるが、概要を知るには便利である。
『Windows 3.1 for IBM-PC/AT互換機 サウンドボード入門』
(1994.5,大田英一郎,株式会社BNN,2800円)は、コンピュータミュージックに興味のある人にとっては有用である。パソコンミュージックの発展史、現状、サウンドボードの原理などが解説されている。サウンドボード別の聞き比べCDが付いている。
【音声情報データベース】
工学分野に関しては、『音響学会誌』を参照すればほとんどのものがカバーできる。論文数も多くここで扱っている分野と異なるので、具体的な論文名は省略する。
国語国文学分野のものは、データベース自体が存在しないので具体的なデータベースに関するものはないのだが、方法論、考え方に関して書かれていて、しかも入手可能なものとしては次のようなものがある。
『日本語学』(1989.3「特集 音声」 明治書院)の「音声データベースの構想」(板橋秀一)では、音声データベースの構成、作成方法、管理と利用などについて一通り説明されており有用である。
『日本語学』(1991.8「特集 新しいデータ・新しい研究」 明治書院)の「音声データベース
-実験音声学の立場から-」(壇辻正剛)では、データベース化の作業のうち、主にセグメンテーション(分節)、ラベリング(音声記号化)の紹介がなされている。
「日本語音声」関連のものとしては、上記『日本語学』(1989.3「特集 音声」
明治書院)の「現代の日本語音声研究の課題」(杉藤美代子)に研究の概要が述べられている。具体的な成果としては研究期間中に刊行された50冊を越える報告書があるが、これらは入手困難である。唯一市販されているものとしては、『国際化する日本語
話し言葉の科学と音声教育』(1993.8,第7回「大学と科学」公開シンポジウム組織委員会編,クバプロ,3000円)がある。「日本語音声」の成果をシンポジウムとして一般公開したものをまとめたもので、研究の全体像がつかめる。
本文中にふれた「日本語音声」関連のデータベース(CD,CD-ROM)は報告書同様、公開されておらず一般には入手できない。作成したCDの枚数自体に余裕がないという事情もあるが、できるだけ早く、せめてアナログテープあるいはDATにダビングしたものを公開し、実費程度で利用できるサービスを始めることが望まれる。
ただし本文中でふれた『日本主要都市方言音声データベース(JCMD)』に関しては、1994年6月よりモニターという形で利用サービスをおこなっている。詳細は「JCMD作成委員会」宛にお問い合わせいただきたい(連絡先はDB-West事務局と同じ)。